
How We Built an Auditable Financial Reasoning Engine That Explains Itself
TL;DR
- Large language models are good at interpreting questions and writing explanations, but unreliable for exact financial arithmetic and strict metric definitions.
- Statement splits responsibilities: the model produces a structured plan and a compute procedure, while a deterministic engine performs retrieval and math.
- Natural-language ambiguity is removed early by resolving phrases like “last quarter” into explicit, recorded parameters (date ranges, entities, filters).
- Each run persists a replayable reasoning object—plan, resolved parameters, retrieval outputs/constraints, computation procedure, and final answer—so results are inspectable and reproducible.
- When something breaks, failures surface as machine-readable runtime errors, enabling targeted fixes and retries without quietly changing what the user asked.
- Explanations are generated from the same execution artifacts, keeping the narrative tied to the actual computation rather than “plausible-sounding” prose.
In our earlier article, we made a straightforward claim: large language models are strong at language understanding, but they are not reliable execution environments for exact financial computation. They can describe a metric, explain a trend, or draft a summary very well. But if you let them directly perform arithmetic or enforce business definitions, they can drift, improvise, or lose precision.
In financial planning, these errors, even if rare, can have catastrophic and irreversible consequences.
So instead of treating the model as both a reasoning layer and a computation layer, we split those responsibilities. We let the model handle interpretation, planning, and explanation while a deterministic runtime handles data retrieval and math. This article explains what that design became in practice: a financial reasoning engine that does not merely return answers, but produces inspectable reasoning artifacts alongside them.
The Core Design Principle: Separate Planning from Execution
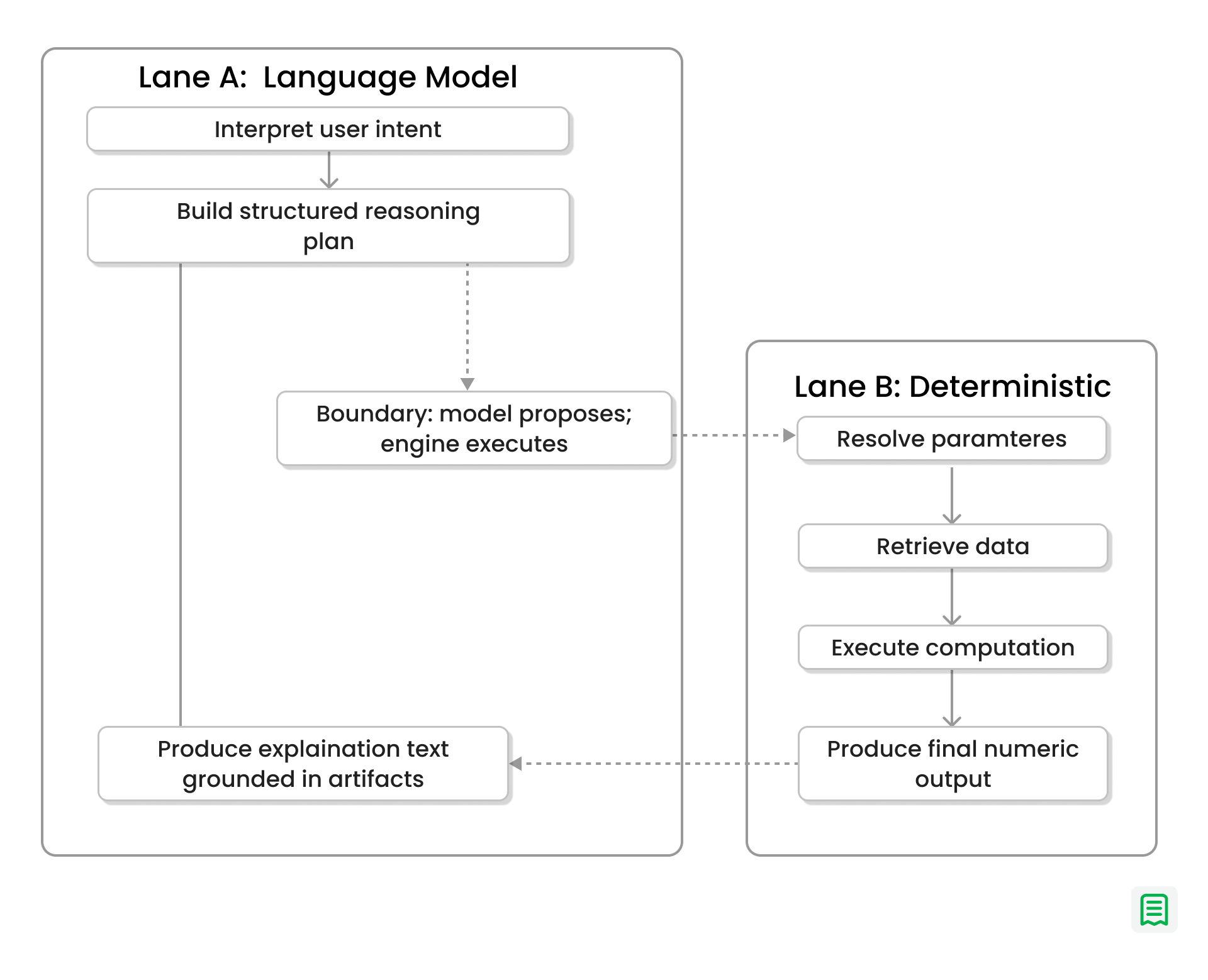
When a user asks a question such as “How did revenue growth change last quarter?”, the system does not immediately generate a narrative response and attach a number to it.
It first treats the request as a reasoning problem.
The language model interprets the question, identifies the informational requirements, and constructs a structured plan for how the answer should be produced. In simple cases, that may involve a small number of retrieval and transformation steps. In more complex cases, the plan may involve multiple intermediate values, temporal comparisons, and dependent computations.
Crucially, the model is constrained to planning. It does not perform the final arithmetic itself. The model specifies what should be computed and why; the engine determines how it is computed and what the result is.
Data Retrieval Is Parameterized and Reproducible
Once a plan is produced, it moves into a deterministic execution path.
At this stage, the system resolves the question into explicit runtime parameters. Relative phrases such as “last quarter,” “this year,” or “month-over-month” are translated into concrete date ranges. Any referenced entities, filters, or segments are resolved to exact values before execution continues.
This matters because ambiguity in natural language is normal, but ambiguity in financial computation is dangerous.
By the time retrieval begins, the system has a fully specified set of parameters, and that specification is recorded as part of the run. The resulting data is not just “fetched”; it is fetched in a way that can later be traced back to the exact interpretation of the original question.
In other words, it delivers answers and keeps a traceable history of the parameters that produced them.
/*
* This is a sample query plan from the LLM.
*/
{
"query_steps": [
{
"step_id": "top_products_by_qty",
"description": "Get top 5 products by total quantity sold in the time window.",
"params": [
{ "name": "project_id", "type": "string", "source": "external" },
{
"name": "start_date",
"type": "date",
"source": "derived",
"derive": "year_start(now, tz)"
},
{
"name": "end_date",
"type": "date",
"source": "derived",
"derive": "now(tz)"
}
],
"query": {
"index": "stripe_invoice_line_items",
"where": [
{ "term": { "project_id": "{{project_id}}" } },
{
"range": {
"created_at": { "gte": "{{start_date}}", "lt": "{{end_date}}" }
}
}
],
"aggs": {
"by_product": {
"terms": {
"field": "product_id",
"size": 5,
"order": { "qty_sum": "desc" }
},
"aggs": { "qty_sum": { "sum": { "field": "quantity" } } }
}
}
}
},
{
"step_id": "fetch_product_metadata",
"description": "Fetch names/SKUs for those product_ids.",
"params": [
{ "name": "project_id", "type": "string", "source": "external" },
{
"name": "product_ids",
"type": "list<string>",
"source": "derived",
"from": "top_products_by_qty.by_product[*].product_id"
}
],
"query": {
"index": "stripe_products",
"where": [
{ "term": { "project_id": "{{project_id}}" } },
{ "terms": { "id": "{{product_ids}}" } }
],
"select": ["id", "name", "sku"]
}
}
]
}
Computation Is Executed as Deterministic Program Logic
After data retrieval, the system moves to the computation phase.
Here, the language model contributes again, but not as a calculator. Instead, it produces a compact, structured computation program that describes the sequence of transformations required to derive the answer. Conceptually, this behaves like a constrained intermediate representation: load values, transform them, aggregate them, compare them, and format the result.
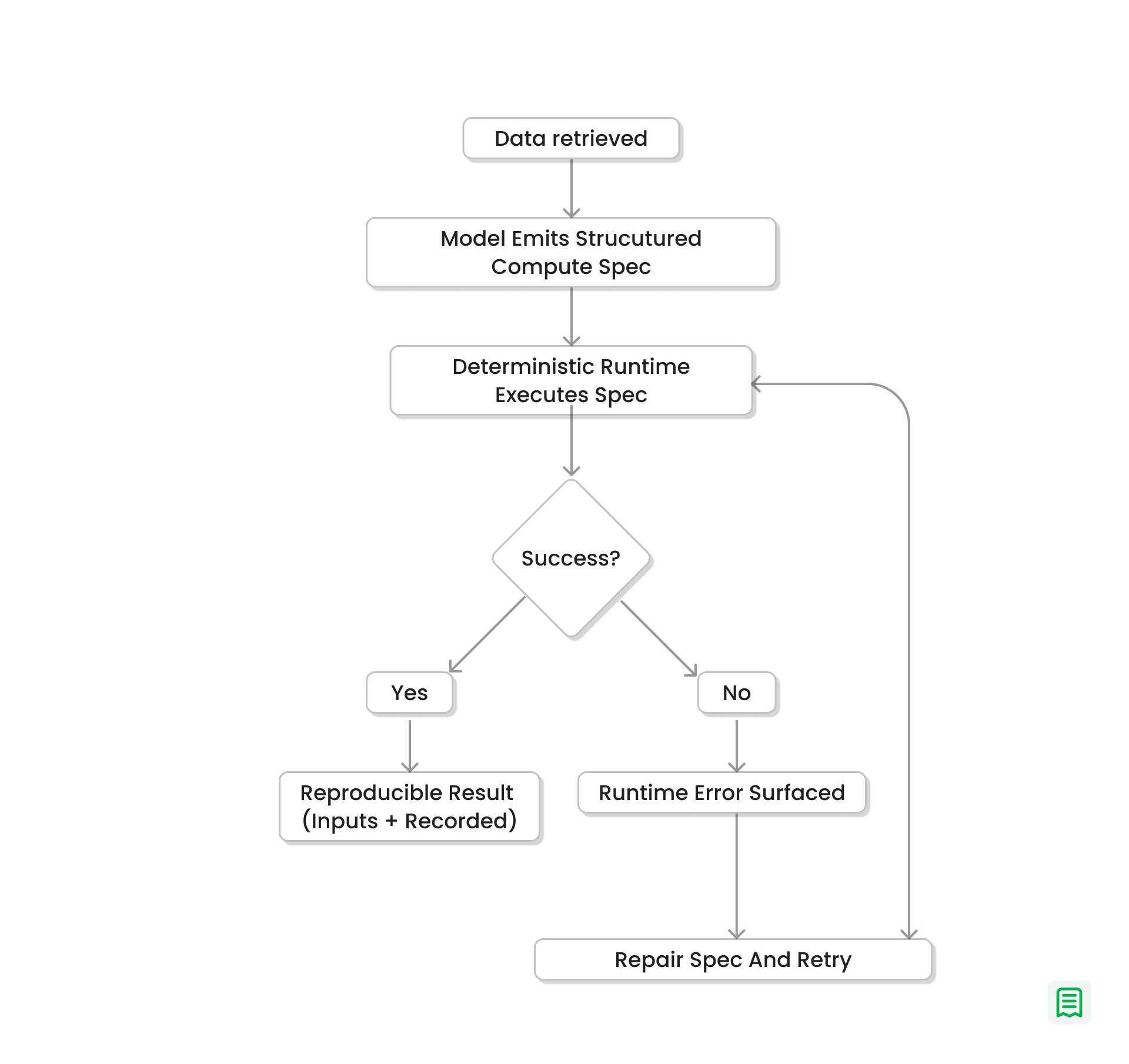
That program is then executed by a deterministic runtime.
This is the key difference from prompt-only reasoning. Rather than calculating in text, the model emits a formal compute specification that the engine runs on the actual retrieved records.
If execution succeeds, we can reproduce the same output later because we have the full set of inputs that actually drove the answer:
- the resolved parameters (what “this quarter” expanded to),
- the retrieval constraints or snapshot identifiers,
- and the computation program (filters, joins, group-bys, rounding rules).
Re-running that program against the same inputs produces the same result because the runtime is deterministic and the model is only generating a structured compute specification.
If execution fails, the failure is surfaced as a concrete runtime error.
The error is machine-readable (for example: missing field, type mismatch, empty result set, invalid date range), and it points to the specific step that failed. That makes it possible to log, debug, and handle failures consistently.
This lets the system attempt a targeted repair of the computation program and retry. Each retry is a new program revision with a recorded reason, so the system can recover without silently changing what the question meant.
The result is a closed-loop reasoning process where language remains flexible, but computation remains exact.
Explanations Are Grounded in Execution Artifacts
A common problem in AI-generated financial answers is that the explanation and the number are loosely coupled. The prose sounds plausible, but there is no reliable way to verify whether the explanation corresponds to the actual computation that produced the result.
We designed against that failure mode.
In our system, the explanation is derived from the same artifacts that produced the answer:
- the structured plan,
- the resolved parameters,
- the retrieval outputs,
- and the deterministic computation program.
That means the final response is not just rhetorically coherent; it is structurally tied to an execution trace.
If a user asks why a reported growth rate is what it is, the system can reconstruct the reasoning path from source values through transformation steps to final output.
Every Answer Is Stored as a Replayable Reasoning Object
We also made a deliberate storage decision: each run is persisted as a full reasoning artifact rather than a final text response plus logs.
That artifact includes:
- the plan,
- the resolved interpretation of the question,
- the computation procedure, and
- the generated answer.
The practical effect is that answers become inspectable objects rather than ephemeral model outputs.
This improves debugging, governance, and trust at the same time.
From an engineering perspective, it gives us a stable substrate for analysis and improvement. From a product perspective, it allows teams to revisit prior answers and understand how they were produced. From an audit perspective, it makes it possible to examine the reasoning chain without relying on memory, screenshots, or prompt history reconstruction.
Replayability Turns Historical Answers into Executable Reasoning
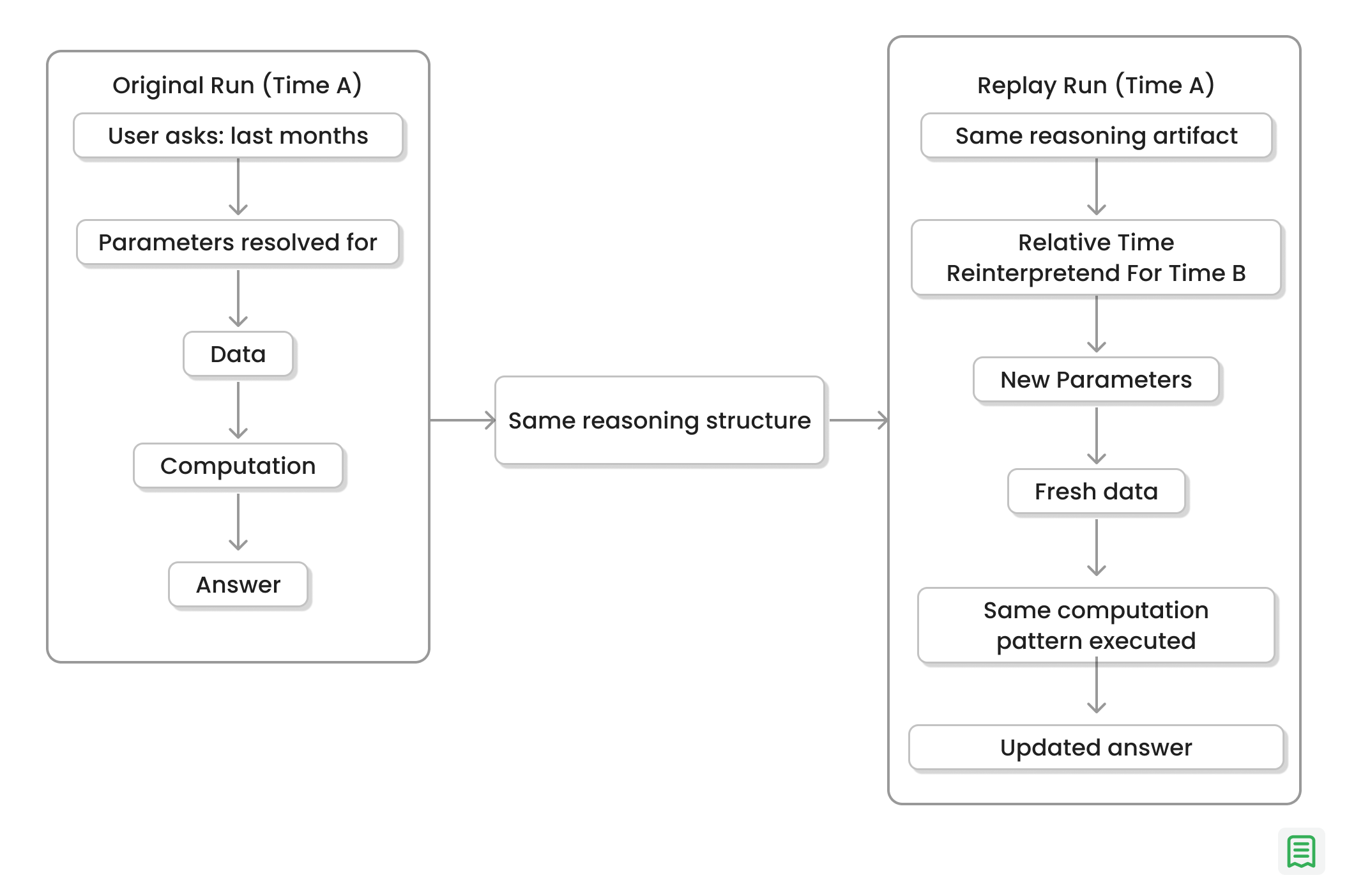
All of the design decisions we discussed make replayability a fundamental feature of the architecture.
Because the system stores a structured reasoning artifact, a previous answer can be re-executed later under updated conditions. If the original question depended on relative time expressions, the engine can reinterpret those references for the current time context while preserving the same reasoning pattern.
For example, a question about “last month’s growth” asked in one period can be replayed in a later period using the same logical structure but a newly resolved date window. The semantics of the analysis remain stable while the data context updates.
What This Architecture Enables
With this architecture, a financial response becomes a traceable computation with a language interface on top of it. The model still plays a central role—it interprets intent, constructs plans, and communicates results—but it no longer serves as the source of numeric truth. Numeric truth comes from deterministic execution.
That separation lets us keep the usability benefits of conversational AI without inheriting the reliability problems of unconstrained model arithmetic. It also gives us something that most AI analytics systems still lack: a verifiable bridge between a natural-language question and a reproducible computational result.
Conclusion
In finance, explainability is often treated as a presentation problem: can the system produce a convincing explanation for an answer?
We think that framing is backwards.
Explainability starts at the execution model. If computation is deterministic, parameter resolution is recorded, and the reasoning path is preserved, then explanation becomes a summary of real system behavior.
The language model remains the interface, but the answer is grounded in a pipeline that can be inspected, replayed, and trusted.


