
Prompt Engineering for Financial Reasoning: What We’ve Learned So Far
TL;DR
LLMs are great at sounding confident about financial questions, but unreliable at reasoning about them. They guess when data is missing, blur time boundaries, mix logic with explanation, and fail silently when asked to do too much at once.
To fix this, we:
- Stopped using a single prompt as a catch-all brain.
- Split reasoning into clear roles (routing, planning, computing, explaining).
- Forced strict, structured outputs instead of free-form text.
- Made time, context, and data limitations explicit.
- Taught the system to fail honestly instead of guessing.
- Optimized prompts to think in batches, not one step at a time.
We now use the LLM only to:
- Understand intent,
- Plan the reasoning steps,
- And translate results into human language.
- Everything else math, data handling, structure, and consistency is enforced by the system.
Result: you still get natural, conversational financial answers but they’re predictable, composable, debuggable, and trustworthy instead of polished guesses.
Introduction
At the start, the idea felt obvious: write one good prompt, ask clear questions, and let the model do the rest. That approach works surprisingly well for summaries, explanations, and everyday reasoning. So it felt reasonable to assume it would work just as well for financial questions.
It didn’t. The first signs were subtle. Answers sounded confident but skipped important numbers. Some responses looked polished yet fell apart when checked closely. Others gave different answers to the same question, depending on how it was phrased. Nothing was completely broken, but nothing was truly reliable either.
That’s when it became clear that financial questions play by different rules. They depend on time, context, incomplete data, and precise definitions. A small misunderstanding doesn’t just make an answer messy it makes it wrong. And when the model is wrong, it’s often wrong with confidence.
This project forced a hard rethink. Prompting wasn’t just about asking better questions anymore. It was about designing guardrails, roles, and structure around how reasoning happens. What started as a prompt-writing exercise slowly turned into a lesson in building systems that help language models think more carefully, especially when the stakes are high.
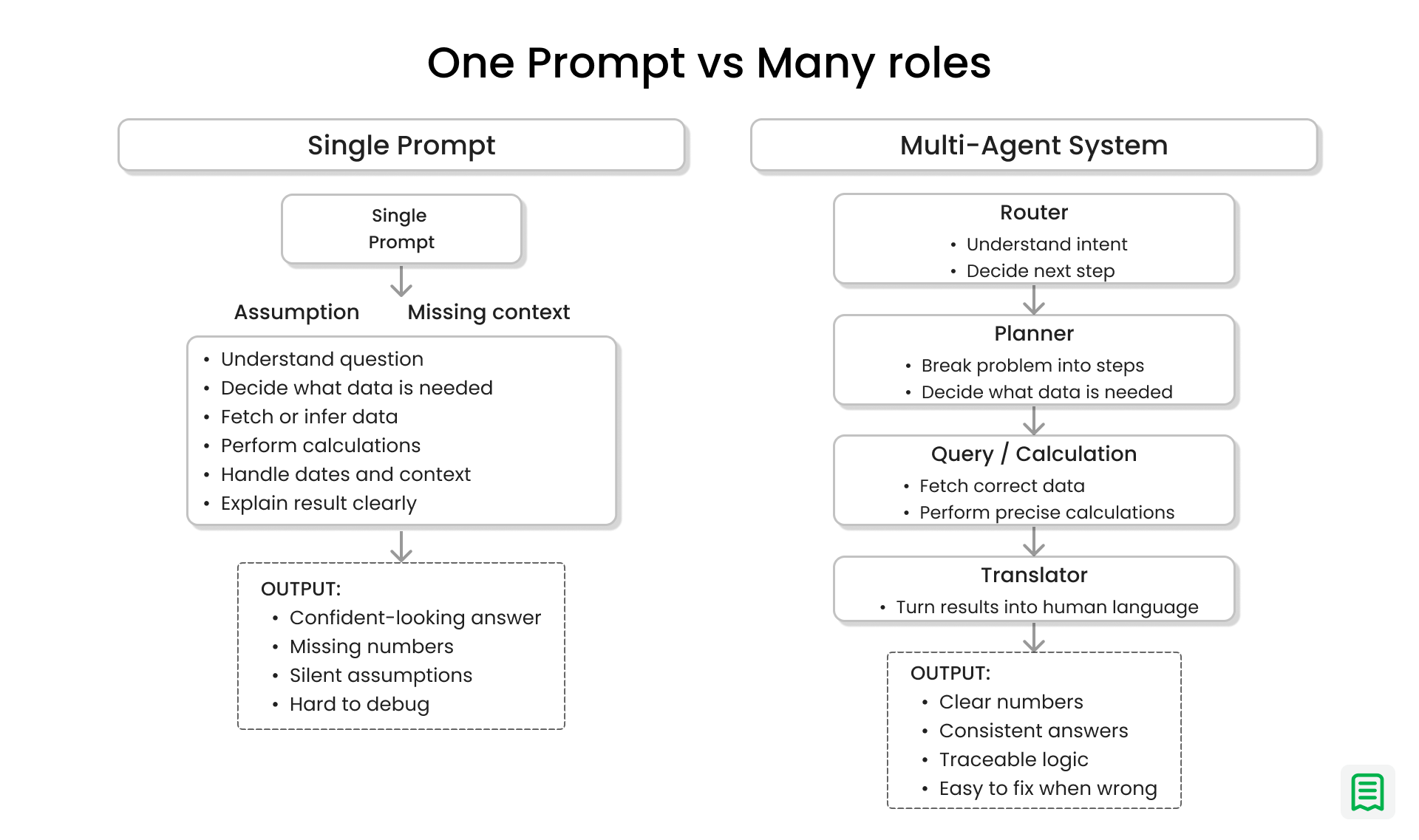
Why One Brain Was Never Going to Be Enough
At some point, it became obvious that the problem wasn’t the wording of the prompt it was the expectation placed on it. We were asking a single prompt to understand the question, decide what data was needed, fetch or calculate the right numbers, interpret the results, and then explain everything clearly to a human. That’s a lot of responsibility for one “brain,” especially when financial questions tend to mix logic, data, and explanation in the same breath.
Financial reasoning has too many moving parts to be handled reliably in one go. A simple question like “How did revenue change last month?” quietly contains several sub-problems: figuring out what “last month” means, deciding which data source matters, calculating the right metric, and finally translating that result into something a human can understand. When all of this lives inside a single prompt, small mistakes compound quickly. A wrong assumption early on quietly poisons everything that follows.
The turning point came when these steps were separated. Instead of one prompt trying to do everything, each part of the problem was given its own role. One part focused only on understanding and routing the question. Another planned what data was needed. Another handled calculations. Another translated raw results into human language. Once each piece had a narrow job, the system stopped tripping over itself.
The impact was immediate. Answers became more consistent. Errors became easier to spot and fix. When something went wrong, it was clear where it went wrong. Most importantly, the system stopped pretending that financial reasoning was a single act of intelligence. It became a coordinated effort, with each role doing one thing well.
The lesson was simple but powerful: complex reasoning improves when responsibility is divided. Asking one prompt to think like an analyst, a planner, and an advisor at the same time doesn’t make it smarter it makes it fragile.
The Power of Telling an Agent Who It Is
Early on, the agents were given a lot of freedom. The prompts were open-ended, optimistic, and well-intentioned. They asked the model to “analyze,” “figure out,” and “explain” without drawing clear lines around what those words actually meant. The result was predictable in hindsight: the agent tried to do everything at once and did none of it particularly well.
It would over-explain simple things, make assumptions it was never asked to make, and occasionally wander into decisions it had no business taking. One agent would plan, calculate, interpret, and summarize all in the same breath. When something went wrong, it was hard to tell whether the mistake came from misunderstanding the question, choosing the wrong data, or explaining the result poorly.
Things changed when each agent was told exactly who it was and where its job ended. One agent was only allowed to decide whether a question needed deeper analysis. Another was only allowed to plan the steps, not compute results. Another could transform numbers into human language but was forbidden from inventing insights. These constraints didn’t make the agents weaker they made them calmer and more predictable.
Interestingly, reducing freedom improved quality. By narrowing what each agent was allowed to do, creativity was pushed out of places where it caused harm, like guessing missing data or reinterpreting numbers. What remained was the kind of creativity that mattered: choosing the right next step, framing an explanation clearly, or asking for clarification when needed.
The lesson was clear and repeated itself across the system: clarity beats cleverness every time. Agents don’t need to be smart in every direction. They need to know their role, respect their limits, and trust that someone else in the system will handle the rest.
JSON Structure Evolution: From Words to Working Systems
At first, letting the model “just explain things” felt natural. The responses sounded fluent, thoughtful, and human. They read like something a person might write after looking at the data for a few minutes. For early experiments, that felt like success.
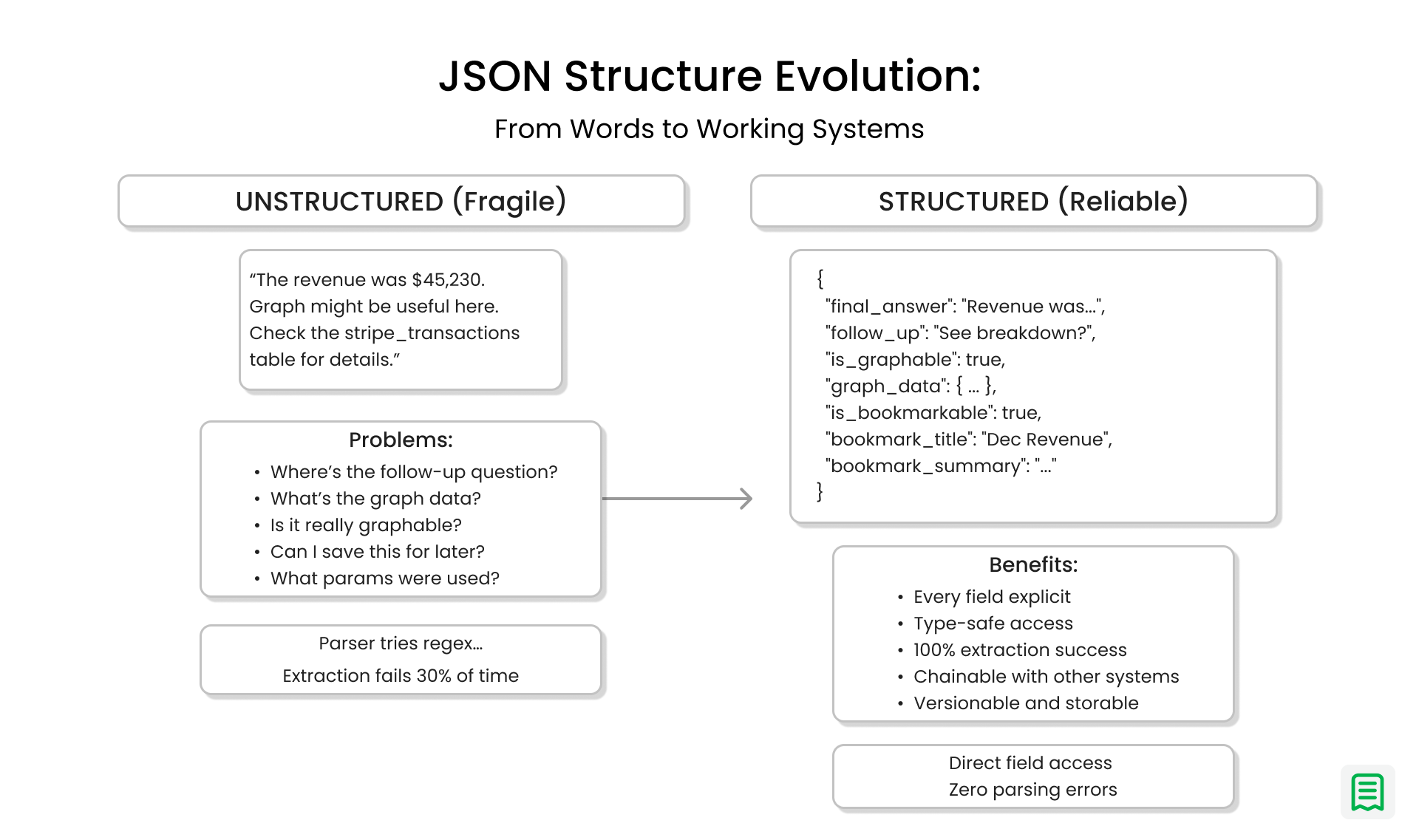
The problem only showed up once those explanations had to flow through a real system powering charts, follow-up questions, saved views, and replays. Every response looked slightly different. Important details appeared in new places each time. Some answers included numbers, others implied them. What read well to a human was unpredictable for software.
The breaking point came when a single missing piece caused an entire response to fail silently. The model had answered the question correctly, but because one expected field wasn’t present, the rest of the system couldn’t use it. No chart. No follow-up. Nothing to save. That moment made something clear: good writing alone isn’t enough in production. Consistency matters more than eloquence.
Early responses were plain text, and they looked like this:
“Revenue increased last month compared to the previous one. March performed better than February, and the trend looks positive overall. You may want to check expenses next.”
To a human, this is perfectly fine.
To a system, it’s a mess.
Where is the actual number?
Is this answer graphable?
Is “check expenses next” a suggestion or just commentary?
Should this be saved as a snapshot?
There’s no reliable way to know. Every downstream step has to guess. Parsers try to extract meaning from sentences. Regex rules pile up. Eventually, something breaks.
Introducing strict structure changed everything.
Instead of hoping the model would remember what to include, every agent was required to respond in a fixed shape. Certain fields always existed. Optional pieces were clearly marked. There was no guessing, no scraping fragile sentences to extract meaning. The model stopped being a loose narrator and started behaving like a dependable system component.
The same answer, expressed with structure, looked like this:
{
"final_answer": "Revenue increased month over month, with March outperforming February.",
"follow_up": "Would you like to review expenses for the same period?",
"is_graphable": true,
"graph_data": {
"type": "line",
"title": "Monthly Revenue Trend",
"value_map": {
"February 2025": 120000,
"March 2025": 145000
}
},
"is_bookmarkable": true
}
Nothing about this is more “intelligent” in a human sense but it’s infinitely more useful. Every piece of information has a place. Nothing needs to be inferred. The system knows exactly what to do next.
This is where composability starts to matter. Because the output is predictable, other parts of the system can rely on it. The graph renderer doesn’t guess. The UI knows whether to show a chart. Follow-up questions can be chained naturally. The same response can be saved, replayed, or updated later without rewriting logic.
What was surprising was how much this improved the quality of the answers themselves. With structure in place, the model spent less effort deciding how to respond and more effort deciding what was correct. Errors became easier to detect. Reliability went up across the board.
The key insight was simple but lasting: structure turns language into infrastructure. JSON didn’t limit what the model could say it made what it said usable, repeatable, and safe at scale.
Forcing the Model to Think Before It Acts (ReAct)
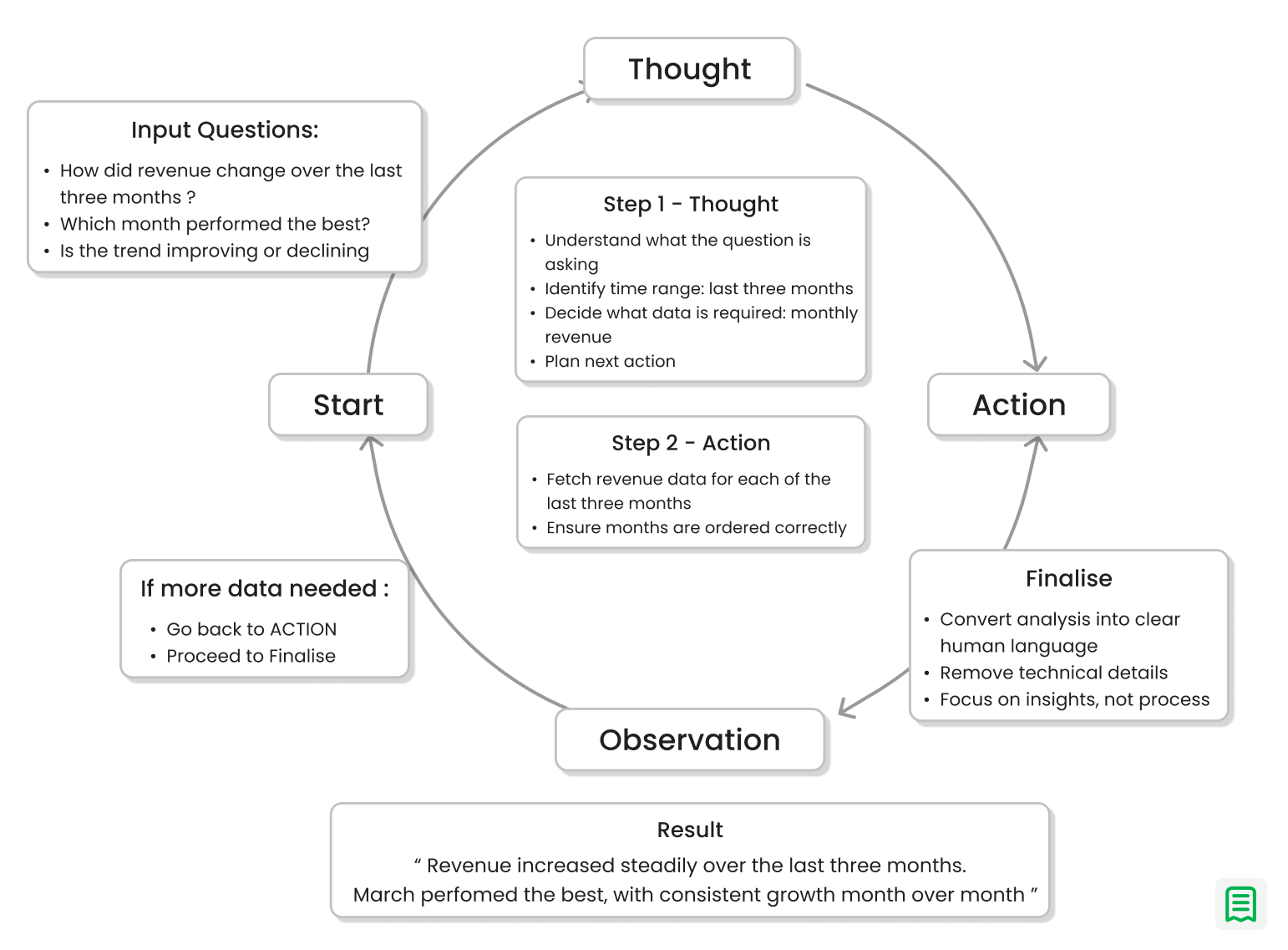
One of the most frustrating parts of early versions of the system was failure without explanation. A response would be wrong or incomplete, and there was no clear reason why. The model hadn’t made an obvious mistake it had simply skipped a step, assumed something silently, or taken a shortcut no one could see. Without visibility into its reasoning, fixing these issues felt like guessing in the dark.
That changed when the model was forced to think before it acted. Instead of jumping straight to an answer, it had to first explain what it planned to do next. Every step followed a simple rhythm: decide, act, observe, then decide again. This small shift exposed the logic that was previously hidden and made the model’s behavior far more predictable.
For example, consider a question like, “How did revenue change over the last three months?” Before, the model might jump straight to a summary, sometimes mixing months, sometimes missing one entirely. With explicit reasoning, the process became visible: first, identify the exact three months; then, fetch revenue for each month; then, compare them in order; and only then, explain the change. When something went wrong say a month was missing it was immediately obvious where the breakdown occurred.
Seeing this “thinking path” changed how the system was built and maintained. Debugging no longer meant rephrasing prompts and hoping for better luck. It meant adjusting a specific step in the reasoning process. Over time, this made the system easier to trust, because its decisions were no longer hidden behind polished language.
The lesson was clear: transparency creates trust and control. When a model shows how it arrives at an answer, you don’t just get better results you get a system you can actually manage.
Time Is the Hardest Part of Financial Questions
Time turned out to be the most deceptive part of financial questions. On the surface, phrases like “last month” or “recent performance” sound harmless. In practice, they kept meaning different things depending on when the question was asked, what had been discussed earlier, and which data window the system silently assumed. Two identical questions asked a few days apart could produce different answers, both technically correct and yet deeply confusing.
The problem became worse in follow-up questions. A user might ask, “How did revenue perform last month?” and then follow with, “What about expenses?” Without remembering the earlier context, the system would often treat the second question as brand new sometimes using a different time range entirely. The answer would look reasonable in isolation but completely wrong in the conversation. This kind of error is subtle, because nothing crashes. The numbers just stop lining up.
That’s when temporal awareness stopped being an afterthought and became a core requirement. Time references had to be resolved explicitly. Relative phrases needed to be anchored to real dates. Follow-up questions had to inherit context instead of resetting it. The system needed to understand not just what was being asked, but when it was being asked in relation to everything else.
The lesson here is easy to miss but critical: financial answers without time context are quietly wrong. They don’t scream error. They simply erode trust, one slightly-off answer at a time.
Learning to Distrust Data On Purpose
One of the most uncomfortable moments in this project came from an answer that looked perfect and was completely wrong. The model had been shown a small sample of data meant only to describe structure, not totals. But it treated that sample as if it were complete. The result was a confident explanation built on numbers that never represented the full picture.
This wasn’t a bug in the system. It was a natural behavior of language models. When something is missing or unclear, they try to be helpful by filling in the gaps. In everyday writing, that instinct is useful. In financial reasoning, it’s dangerous. Guessing, even politely, turns uncertainty into false certainty.
The fix wasn’t better phrasing it was explicit restriction. The prompts had to clearly state what the data was and what it wasn’t. They had to forbid certain actions outright, like doing math on sampled values or assuming missing entries didn’t exist. These warnings weren’t suggestions. They were hard rules designed to interrupt the model’s optimism before it caused harm.
Once those guardrails were in place, the behavior changed noticeably. The model became more cautious. It asked for clarification when needed. It accepted partial answers instead of inventing complete ones. The system traded a bit of confidence for a lot of correctness.
The lesson was clear: prompts must protect against optimism. In financial systems, it’s better to admit uncertainty than to deliver a confident lie.
Speaking Human, Not System
One of the quiet challenges in this project wasn’t getting the right numbers it was deciding how much of the process to show. Financial systems are full of technical details: data sources, schemas, calculations, edge cases. All of that matters for correctness, but almost none of it matters to the person asking the question. What they want is a clear answer they can trust.
This created a constant tension between accuracy and readability. Exposing too much detail made answers harder to understand and easier to doubt. Hiding too much risked oversimplifying or, worse, misleading. The goal became finding the narrow path where the answer stayed faithful to the data without dragging the user through the machinery behind it.
A key realization was that users don’t care how data was fetched they care what it means. Whether a number came from one table or five, or whether it required three steps or ten, is irrelevant outside the system. So the agents were taught to stop talking like databases and start talking like advisors. No field names. No technical labels. Just clear explanations grounded in the data.
When this worked, the system felt almost invisible. The complexity didn’t disappear it was simply hidden behind thoughtful translation. The answers became easier to read, easier to act on, and easier to trust.
The lesson was simple and powerful: the best systems feel simple on the surface. Not because they are simple, but because they respect the user’s perspective.
Vague Instructions Create Vague Results
Early on, many of the answers fell into the same frustrating category: almost right. The numbers were correct, but the format changed from response to response. Dates appeared sometimes, disappeared other times, or showed up in different styles. Nothing was technically broken, yet nothing felt dependable. Every small variation forced extra checks, extra parsing, and extra doubt.
The root cause was vague instruction. Telling a model to “format nicely” or “present clearly” leaves too much room for interpretation. What looks clear to one response looks different in the next. That flexibility feels helpful at first, but at scale it turns into inconsistency.
Things improved when the guidance became uncomfortably specific. Dates had one format and only one format. Currency always included a symbol. Headings followed a fixed structure. Even rules like “don’t mention dates unless they matter” removed an entire category of unnecessary noise. These tiny constraints quietly eliminated whole classes of errors.
For example, instead of asking the model to “show monthly revenue,” the prompt required month names in a fixed order and a single date style. The output stopped drifting. Comparisons became reliable. Follow-up questions stopped breaking assumptions.
What felt like over-specification at the beginning ended up saving time everywhere else. There was less cleanup, fewer edge cases, and far less guessing about intent.
The lesson here is simple: precision scales better than flexibility. Clear rules give models less room to wander and give systems more room to grow.
Designing for Failure Instead of Hoping for Success
Financial data is rarely perfect. Numbers arrive late, sources go missing, and gaps appear without warning. Early versions of the system behaved as if completeness was guaranteed. When data was missing, the model either stalled or quietly produced partial answers that looked finished. Both outcomes were dangerous.
Silence turned out to be worse than uncertainty. An empty or vague response left users guessing whether the system failed or whether there was simply nothing to report. Even worse, partial data sometimes led to confident conclusions built on incomplete information.
The fix was to teach agents how to fail honestly. If data was missing, the response had to say so. If an answer was incomplete, it had to explain why and what was known so far. For example, instead of stating “Revenue decreased last month,” the system learned to say, “Revenue data for the final week is unavailable, so this reflects a partial view.”
This kind of honesty changed how the system was perceived. Users trusted it more, not less. They understood the limits and could make informed decisions.
The lesson was clear: graceful degradation builds long-term trust. A system that admits uncertainty is far more reliable than one that hides it.
Efficiency Is Part of the Prompt
At first, it was easy to ignore performance. A single extra query here or there didn’t seem expensive, especially when everything worked in small tests. But once real usage began, the cost of “just one more query” added up quickly. Latency increased. Systems slowed down. What felt harmless in a demo became painful at scale.
The issue wasn’t the model it was how the prompts thought about work. Step-by-step reasoning often translated into step-by-step data fetching, even when multiple steps could be handled together. The system was correct, but inefficient.
Things changed when prompts were taught to think in batches. Instead of asking for one month at a time, they asked for all relevant months at once. Instead of repeating similar requests, they grouped them. This small shift reduced load, sped up responses, and made the system more predictable under pressure.
The takeaway was simple but important: prompt engineering isn’t free. Every instruction has a cost. Good prompts don’t just aim for correct answers they respect time, compute, and scale.
Conclusion
This project changed how we think about language models. They aren’t magic oracles waiting for better questions they’re systems that need guidance, boundaries, and structure to behave reliably. The more we treated prompts as isolated pieces of text, the more fragile the results became.
What worked was thinking beyond prompts. Clear roles, strict structure, explicit limits, and careful handling of time and data turned vague reasoning into something dependable. The real shift wasn’t in how questions were asked, but in how reasoning itself was designed.
Prompt engineering, in this sense, stopped being about wording and started being about architecture. We moved from asking models to “figure things out” to building systems that help them reason step by step, fail honestly, and explain clearly.
This approach still isn’t perfect. Edge cases exist. Ambiguous questions still require judgment. Data is still messy. But the difference is control. When things break now, we understand why and we know where to fix them.
That may be the most important lesson of all: prompt engineering isn’t about clever prompts. It’s about designing systems that make good reasoning possible.

