
RAG for Finance: How to Build Context Aware Retrieval Systems
TL;DR
Thesis:
Financial AI fails when it generates answers in isolation; it succeeds when every answer is grounded in verifiable source data retrieved at query time.
Why the current approach breaks:
- Pre-trained models go stale the moment regulations or filings change.
- Confident but unsupported answers (“hallucinations”) are operationally dangerous.
- Financial data is fragmented across documents, systems, and formats.
- Long, unfocused context degrades accuracy and increases cost.
What works better:
- Retrieval-first architecture that injects only relevant, auditable facts.
- Precise retrieval using metadata, not just semantic similarity.
- Minimal, high-signal context passed to the model.
- Clear separation of retrieval (facts) and generation (reasoning).
Outcome:
AI systems that explain their answers, withstand audits, and support real financial decisions instead of speculative ones.
Introduction
The global financial system operates on an ocean of data market tickers, regulatory filings, analyst reports, and internal ledgers. When a critical decision is made, a CFO, portfolio manager, or compliance officer cannot accept a black-box answer. They require verifiable, context-aware intelligence.
The current generation of Large Language Models (LLMs), while powerful, falls short here. They suffer from static training data (knowledge cutoff) and the risk of hallucination. This is why the financial sector needs a bridge between the vast, authoritative source documents and the LLM's reasoning engine.
The solution is Retrieval-Augmented Generation (RAG). RAG is a sophisticated framework that transforms the way financial systems "think" by providing LLMs with real-time, verifiable context from your proprietary data at the moment of query. It moves AI from a passive knowledge repository to an active, contextual reasoning partner.
What is RAG (Retrieval-Augmented Generation) and the advantages
Retrieval-Augmented Generation (RAG) is designed around a retrieval-first approach that clearly separates knowledge retrieval from language generation, ensuring that factual information is obtained before any response is generated.
RAG comes with below advantages:
- Overcoming LLM knowledge cutoffs: RAG enables real-time access to new financial data, eliminating reliance on a model’s static training knowledge and addressing rapidly changing markets and regulations.
- Query-time retrieval and context injection: When a user submits a query, the system retrieves the most semantically similar document chunks and injects them into the LLM’s context along with the question, grounding the response in verifiable source material.
- Reduction of hallucinations: By forcing the model to rely on retrieved documents, RAG significantly reduces the risk of confident but incorrect answers, which is critical in financial analysis.
- Trust, explainability, and auditability: Every response can be traced back to a specific filing, page, or paragraph, providing the transparency and accountability required in high-stakes financial environments.
Retrieval-based context eliminates the high-risk hallucination problem, transforming the LLM into a reliable financial analyst that cites its work. Below is the comparison of Original Query Response vs. Contextual Query Response.
Consider the question: "Explain the Q3 revenue dip for Acme Corp."
| Model | Response Type | Example Output | Risk Profile |
|---|---|---|---|
| Original LLM (Isolation) | Hallucinated or Generic | "Acme Corp's Q3 revenue dip was likely due to general economic headwinds and supply chain issues reported across the retail sector." (Plausible but fabricated.) | HIGH (Untraceable, potentially false) |
| Contextual LLM (RAG-Powered) | Grounded and Specific | "Acme Corp's Q3 revenue dipped due to a 15% decline in its European market segment from the Q3 statements. The company explicitly cited a regulatory change in Germany as the primary driver, not general supply chain issues." (Verifiable, accurate reasoning.) | LOW (Auditable, grounded in source) |
How RAG Differs from Other AI Approaches
| Approach | Primary Goal | Change Model Weights? | Financial Use Case |
|---|---|---|---|
| RAG | Inject dynamic, up-to-date facts | No (Uses external retrieval) | Real-time regulatory Q&A, Earnings call analysis |
| Fine-Tuning (FT) | Change behaviour, style, or format | Yes (Updates internal weights) | Generating boilerplate legal clauses, Adopting a specific corporate tone |
| Few-Shot Learning | Steer output with examples in the prompt | No | One-off classification of transaction types |
RAG complements fine-tuning. You might fine-tune an LLM to speak like a compliance officer (behaviour) and then use RAG to provide it with the latest compliance circulars (facts). RAG is the best tool for real-time knowledge injection and verifiable grounding.
Why Retrieval-Augmented Generation Matters in Finance
Large language models have a fixed knowledge cutoff, which makes them unsuitable for finance without augmentation. Markets, filings, and regulations change continuously. Retrieval-Augmented Generation (RAG) eliminates this limitation by grounding responses in real-time, authoritative data rather than static model memory.
Grounding is critical in finance: a confident but incorrect answer is materially worse than no answer. RAG constrains generation to retrieved sources, enabling verifiable, explainable outputs that can be traced to specific filings, sections, or disclosures.
How Financial RAG Systems Work
A production-grade financial RAG system operates across three tightly coupled layers:
- Query Understanding – Interprets intent and decomposes complex financial questions (e.g., cross-company or time-based comparisons).
- Document Retrieval – Uses vector search, keyword matching, and metadata filters to surface the most relevant filings and reports.
- Contextual Synthesis – Generates answers strictly from retrieved evidence, prioritising accuracy over fluency.
To improve precision, financial RAG systems often use domain-specific embedding that distinguish nuanced financial concepts. Advanced implementations integrate Knowledge Graphs to resolve entities and relationships deterministically before retrieving supporting documents, combining structured accuracy with semantic depth.
Applying RAG in Production: How Context-Aware Retrieval Improved Our Financial System
Below, we describe how we implemented RAG in our production environment, the key challenges we encountered around context loss, data fragmentation, and retrieval accuracy, and how context-aware retrieval helped us address these issues to materially improve the performance, reliability, and interpretability of our financial system.
Challenge 1: The Precision and Performance Problem
As large language models (LLMs) gain the ability to process increasingly large context windows, a new class of challenges has emerged precision degradation and performance inefficiency. While it may seem intuitive to provide the model with as much data as possible, doing so often produces the opposite of the intended outcome.
One of the most common issues is context overload, frequently referred to as the “Lost in the Middle” problem. When an LLM is presented with a very large input such as an entire quarter’s worth of bank statements it struggles to consistently identify and prioritize the most relevant information. Important details may be overlooked, diluted by noise, or misinterpreted entirely.
Closely related is relevance drift, where the model begins to incorporate loosely related or completely irrelevant data into its reasoning. Instead of answering the question directly, the response may wander across unrelated transactions, categories, or time periods, leading to misleading summaries and reduced trust in the output.
From a systems perspective, large contexts also introduce significant latency and cost concerns. Larger prompts require more tokens to process, increasing response times and computational overhead. This makes naïve large-context approaches impractical for real-time or user-facing financial applications.
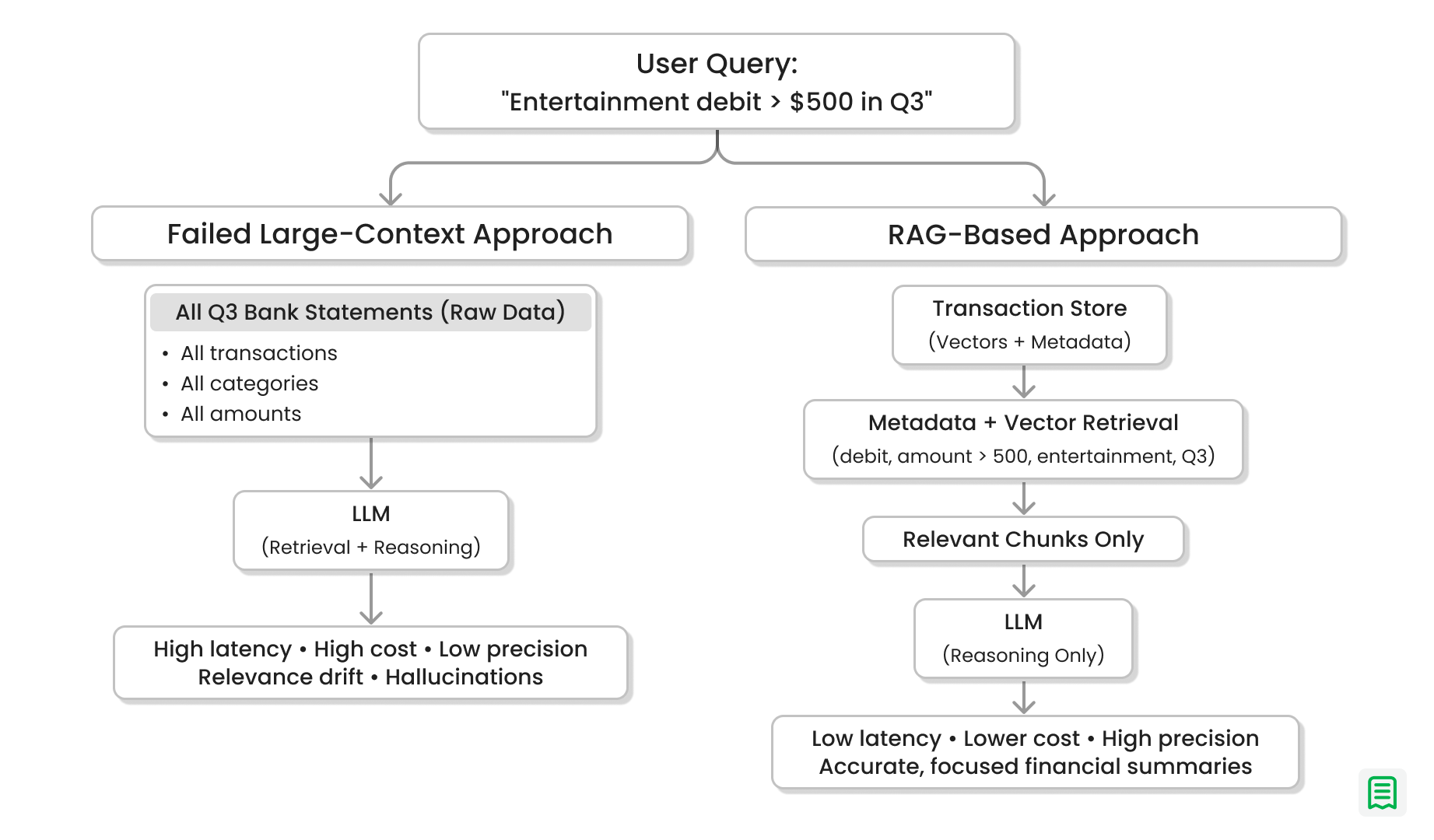
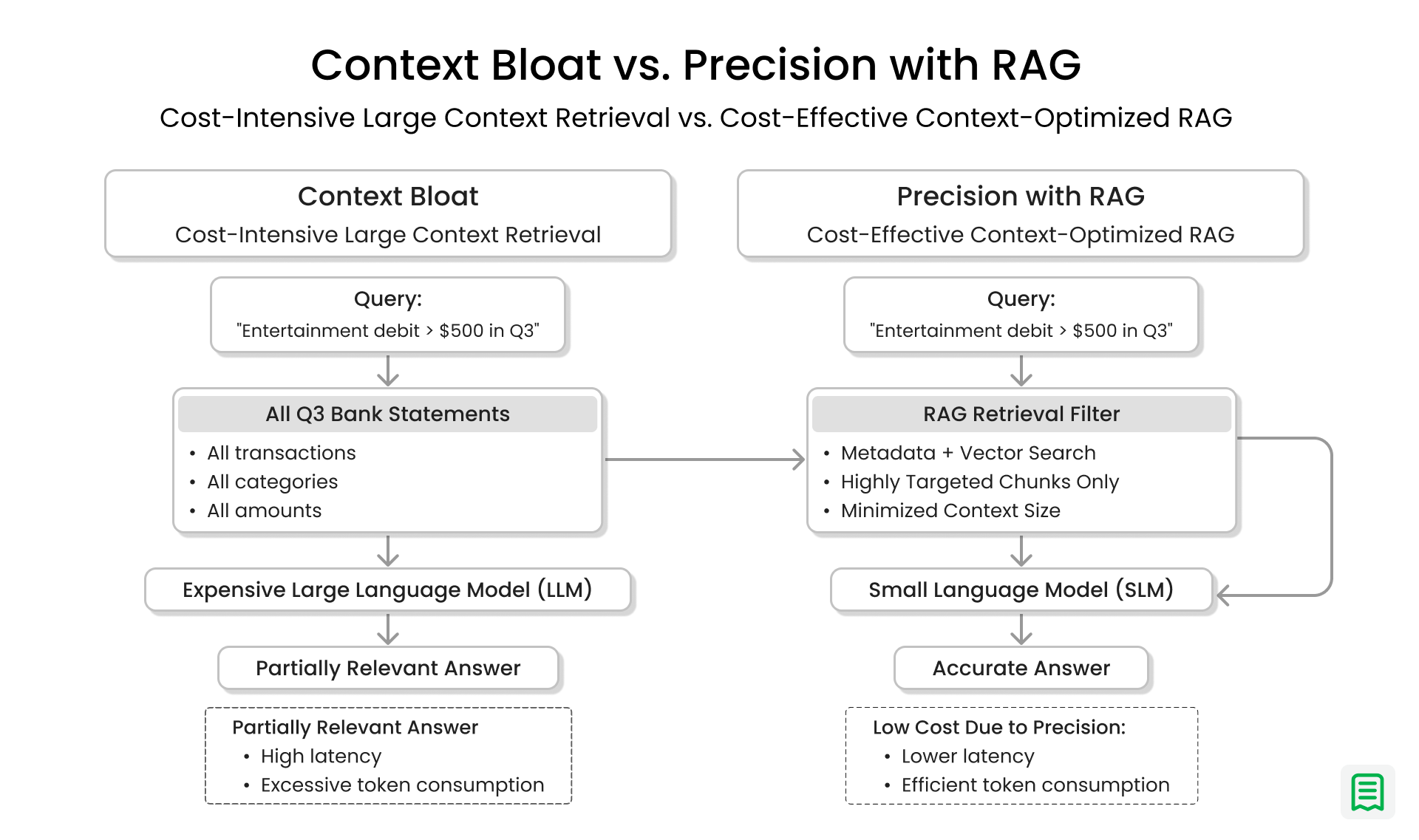
Consider the following query:
“Summarise all debit transactions over $500 categorised as ‘Entertainment’ in Q3.”
Failed Large-Context Approach
A straightforward but flawed approach is to collect all bank statements for Q3 and pass them wholesale to the LLM, expecting it to filter, reason, and summarise internally. In practice, this leads to:
- Excessive context size
- Higher latency and token costs
- Increased hallucinations
- Irrelevant or partially correct answers
The model is forced to do both retrieval and reasoning, which it is not optimised for at scale.
RAG-Based Solution
A Retrieval-Augmented Generation (RAG) architecture addresses these issues by separating retrieval from generation.
Instead of passing all Q3 data to the LLM, the system first performs a highly targeted retrieval step. Using vector search combined with structured metadata filters, the database is queried for only the relevant transaction chunks:
transaction_type = debitamount > 500category = entertainmentfiscal_period = Q3
Only the filtered and contextually relevant documents are retrieved and sent to the LLM. As a result:
- Context size is dramatically reduced
- Precision and factual accuracy improve
- Response times are faster
- Hallucinations are minimised
The size of the context provided to a language model has a direct and measurable impact on latency, cost, and response quality. Contrary to intuition, increasing context length does not consistently improve accuracy. Beyond a certain threshold, it often degrades model performance.
| Context Length (Tokens) | Performance & Cost Impact | Accuracy Impact |
|---|---|---|
| Minimal Context (< 1,000 tokens) | Fast inference and lower operational cost. Fewer tokens result in reduced processing time and significantly lower inference expenses. | Higher accuracy and faithfulness. With limited, high-signal input, the model remains focused on relevant facts, minimizing hallucinations and avoiding the “Lost in the Middle” effect. |
| Long Context (10,000+ tokens) | Increased latency and rising cost. Token consumption grows linearly, leading to slower responses and higher inference spend. | Elevated accuracy risk. The model may rely on irrelevant sections of the input or miss critical facts buried within noisy context. |
| Very Large Context (128,000+ tokens) | Diminishing returns with unstable performance. | Significant accuracy degradation. Context overload becomes dominant, and the model frequently fails to identify or prioritize the correct information. |
In practice, precision not volume drives reliable reasoning. By constraining the LLM’s input to only what matters, Retrieval-Augmented Generation (RAG) enables scalable, cost-efficient, and highly accurate financial summarization. This makes RAG far better suited for real-world analytics and reporting workflows than naïve large-context approaches.
Challenge 2: Designing Cost-Effective Reasoning Systems with RAG
Cost efficiency is one of the most critical design constraints when deploying Large Language Models (LLMs) in production particularly in high-volume domains such as finance. Among all cost drivers, context size plays a disproportionately large role: the larger the input context sent to a model, the higher the inference cost and latency.
Reducing Context Size with RAG
Retrieval-Augmented Generation (RAG) directly addresses this challenge by minimizing the amount of data sent to the model. Rather than passing large, unfiltered datasets such as entire financial records or document repositories to an LLM, RAG introduces a retrieval step that identifies only the most relevant chunks of information.
By performing vector and metadata-based searches upfront, RAG ensures that:
- Only high-signal, query-relevant data is included in the prompt
- Token usage is significantly reduced
- Costs scale linearly with relevance, not dataset size
In practical terms, RAG transforms the LLM from a system that must search and reason into one that only needs to reason dramatically improving cost efficiency.
Leveraging Small Language Models (SLMs)
The retrieval-first nature of RAG unlocks another major optimisation: the strategic use of Small Language Models (SLMs), also known as lightweight models.
For many real-world financial workloads such as transaction classification, structured summarization, compliance checks, or fact verification the full reasoning capacity of a frontier-scale LLM is unnecessary once the correct context has already been retrieved.
This shift delivers several concrete benefits:
- Cost Reduction:SLMs have significantly fewer parameters, resulting in a much lower cost per inference token. At enterprise scale where millions of queries may be processed daily this difference compounds into substantial operational savings.
- Lower Latency:Smaller models execute faster and can often run on commodity hardware or secure, on-premise infrastructure. This makes them ideal for latency-sensitive, real-time financial applications.
- Model-Agnostic Accuracy:RAG demonstrates that context quality matters more than model size. When retrieval is precise and well-tuned, an SLM can achieve accuracy comparable to a much larger model for grounded, retrieval-based tasks.
In effect, RAG decouples intelligence from scale. By pairing high-quality retrieval with appropriately sized models, organisations can deploy financial AI systems that are not only accurate but also scalable, fast, and economically sustainable.
Challenge 3: Making the LLM Up-to-Date: Personalised Context and Interaction History
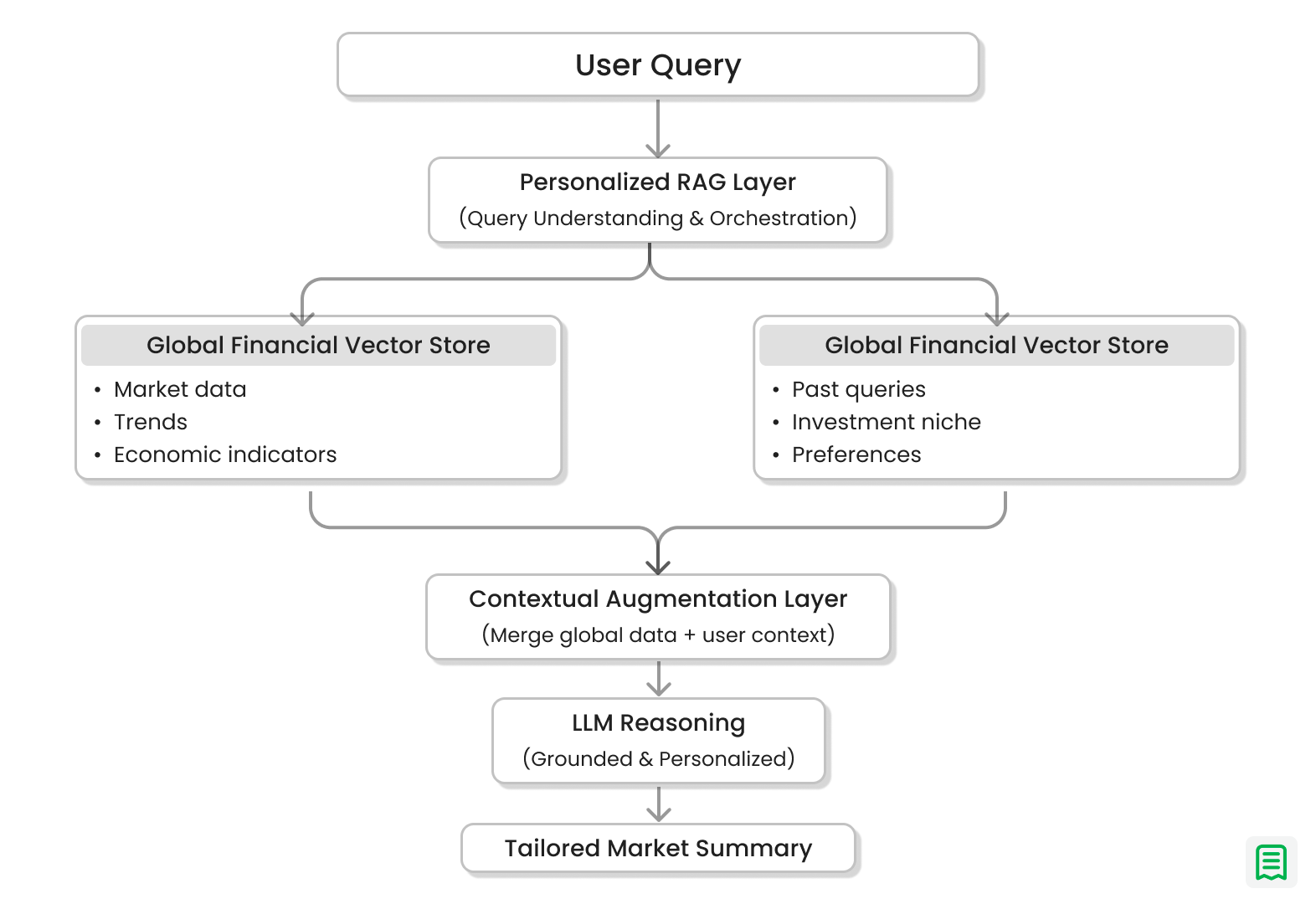
The financial sector requires more than just globally fresh data; it demands personalised, up-to-date relevance. A bank's investment chatbot must evolve not only with market shifts but also with the unique history and niche requirements of each user. Different users often expect different results for the same queries based on their specific portfolios, regulatory frameworks, or preferred risk models.
RAG for User-Specific Evolution (Personalised Context)
RAG is perfectly suited to make the system behave as the user intends, based on their prior interactions. This is achieved by creating a Personalised RAG Layer where the retrieval system stores and references individual user history:
- Storing Interaction Context: Every meaningful user interaction including past queries, specified financial niches (e.g., "focus on emerging markets"), preferred reporting formats, and system feedback (e.g., "that calculation was too broad") is automatically processed, chunked, and stored as an embedding in a dedicated, secure User-Specific Vector Store.
- Up-to-Date Retrieval: When the same user returns, their current query (e.g., "Give me a Q4 market summary") triggers retrieval from two sources simultaneously:
- The Global Financial Vector Store (for the latest market facts).
- The User-Specific Vector Store (for their personalised context).
- Contextual Augmentation: The retrieved user history (e.g., "User's niche is renewable energy stocks," "User prefers analysis based on ESG metrics") is injected into the LLM's prompt alongside the market data.
- Personalised Response: The LLM uses this combined, up-to-date context to tailor the market summary, focusing specifically on renewable energy and highlighting relevant ESG data.
Achieving Predictability by Reducing Randomness
By integrating this historical context, RAG achieves predictability by reducing the randomness in the LLM's output. The system no longer answers a query in isolation; it retrieves its own history with the user, ensuring the response is aligned with the user's previously expressed preferences and niche.
This iterative feedback loop ensures the financial chatbot is not just current with the market but is truly up-to-date and highly relevant to the individual user's needs, making the AI a more effective and trusted partnerThe Real Breakthrough
RAG succeeds where fine-tuning alone fails because it embraces the dynamic nature of finance. Fine-tuning builds static intelligence a model's internal understanding. RAG builds dynamic, data-aware reasoning a system that constantly references the latest, truest source of information.
This is the shift from a model that stores knowledge to a system that truly understands financial context.
Wrapping Up
RAG succeeds in finance because it aligns AI systems with how financial work actually operates: evidence first, reasoning second. Fine-tuning builds static behaviour. RAG enables dynamic, data-aware reasoning grounded in the latest authoritative sources.
Rules of thumb:
- If an answer cannot be sourced, it cannot be trusted.
- Precision beats volume in financial context.
- Metadata is as important as embedding.
- Smaller models work when retrieval is precise.
- Retrieval quality determines output quality.
RAG is not an optimisation. It is the foundation for trustworthy financial AI.


